

Introduction


master status


Manage data like code
Quilt provides versioned, reusable building blocks for analysis in the form of data packages. A data package may contain data of any type or any size.
Quilt does for data what package managers do for code: provide a centralized store of record.
Demo

Benefits
Reproducibility - Imagine source code without versions. Ouch. Why live with un-versioned data? Versioned data makes analysis reproducible by creating unambiguous references to potentially complex data dependencies.
Collaboration and transparency - Data likes to be shared. Quilt offers a unified catalog for finding and sharing data.
Auditing - the registry tracks all reads and writes so that admins know when data are accessed or changed.
Less data prep - the registry abstracts away network, storage, and file format so that users can focus on what they wish to do with the data.
De-duplication - Data are identified by their SHA-256 hash. Duplicate data are written to disk once, for each user. As a result, large, repeated data fragments consume less disk and network bandwidth.
Faster analysis - Serialized data loads 5 to 20 times faster than files. Moreover, specialized storage formats like Apache Parquet minimize I/O bottlenecks so that tools like Presto DB and Hive run faster.
Key concepts
Data package
A Quilt data package is a tree of data wrapped in a Python module. You can think of a package as a miniature, virtualized filesystem accessible to a variety of languages and platforms.
Each Quilt package has a unique handle of the form USER_NAME/PACKAGE_NAME.
Packages are stored in a server-side registry. The registry controls permissions and stores package meta-data, such as the revision history. Each package has a web landing page for documentation, like this one for uciml/iris.
The data in a package are tracked in a hash tree. The tophash for the tree is the hash of all hashes of all data in the package. The combination of a package handle and tophash form a package instance. Package instances are immutable.
Leaf nodes in the package tree are called fragments or objects. Installed fragments are de-duplicated and kept in a local object store.
Package lifecycle
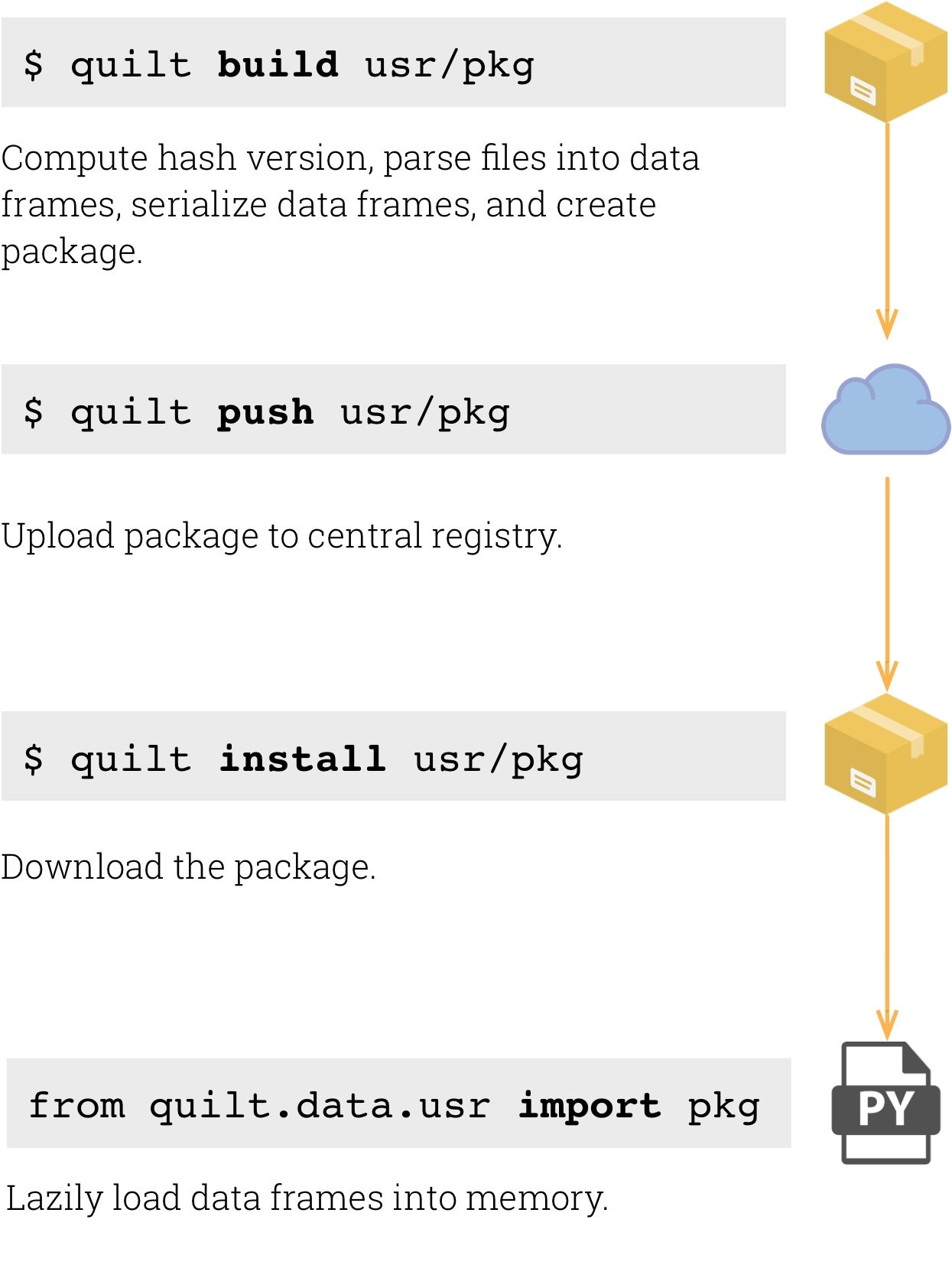
Core commands
build creates a package
build creates a packagebuild hashes and serializes data. All data and metadata are tracked in a hash-tree that specifies the structure of the package.
By default:
Unstructured and semi-structured data are copied "as is" (e.g. JSON, TXT)
You may override the above defaults, for example if you wish data to remain in its original format, with the transform: id setting in build.yml.
push stores a package in a server-side registry
push stores a package in a server-side registryPackages are registered against a Flask/MySQL endpoint that controls permissions and keeps track of where data lives in blob storage (S3 for the Free tier).
install downloads a package
install downloads a packageAfter a permissions check the client receives a signed URL to download the package from blob storage.
Installed packages are stored in a local quilt_modules folder. Type $ quilt ls to see where quilt_modules is located.
import exposes your package to code
import exposes your package to codeQuilt data packages are wrapped in a Python module so that users can import data like code: from quilt.data.USER_NAME import PACKAGE_NAME.
Data import is lazy to minimize I/O. Data are only loaded from disk if and when the user references the data (usually by adding parenthesis to a package path, pkg.foo.bar()).
Service
Quilt is offered as a managed service at quiltdata.com. Alternatively, users can run their own registries (refer to the registry documentation).
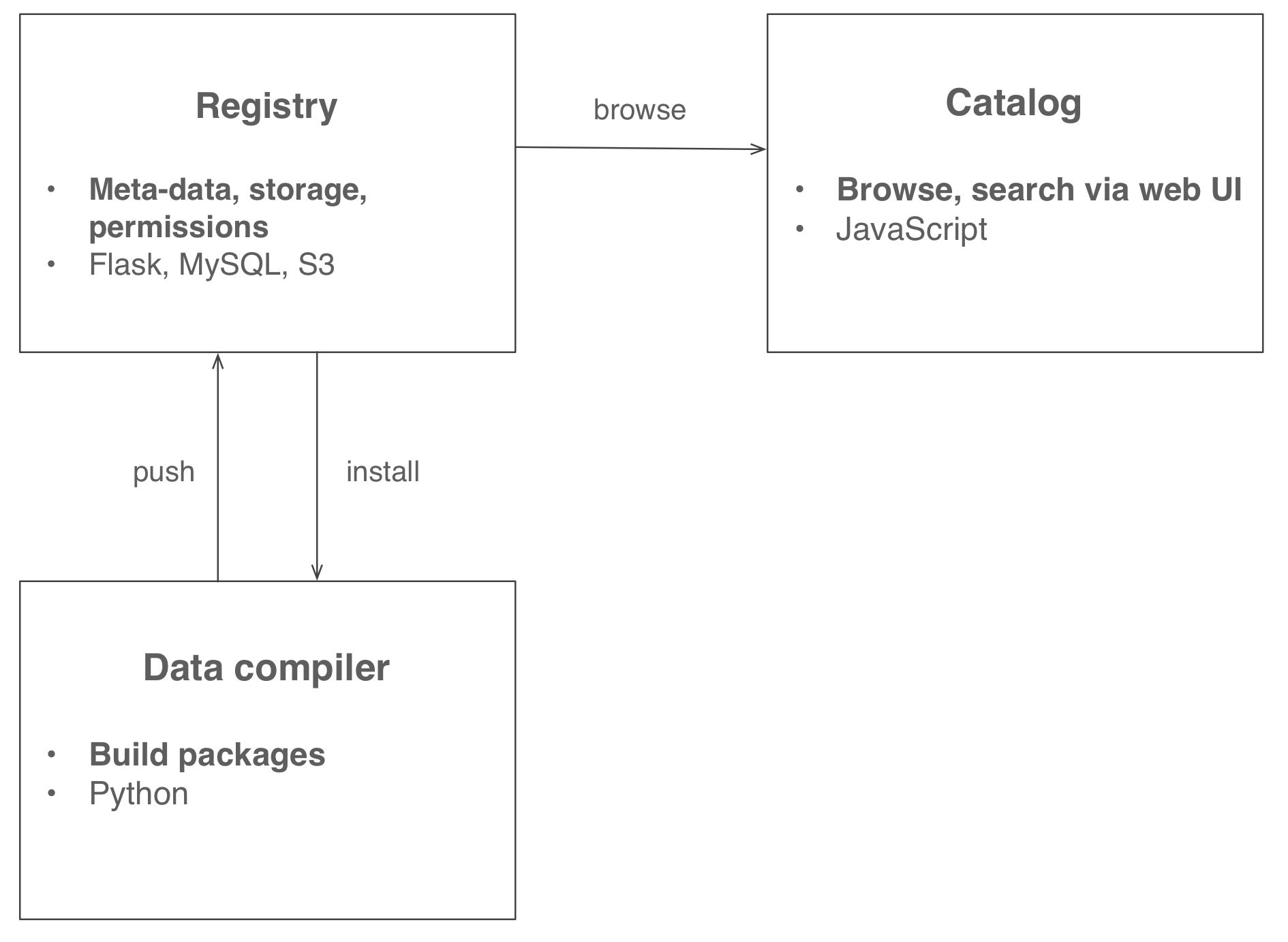
Architecture
Quilt consists of three components. See the contributing docs for further details.
Last updated
Was this helpful?